8. Spark Metastore¶
Let us understand how to interact with metastore tables using Spark based APIs.
8.1. Overview of Spark Metastore¶
Let us get an overview of Spark Metastore and how we can leverage it to manage databases and tables on top of Big Data based file systems such as HDFS, s3 etc.
Quite often we need to deal with structured data and the most popular way of processing structured data is by using Databases, Tables and then SQL.
Spark Metastore (similar to Hive Metastore) will facilitate us to manage databases and tables.
Typically Metastore is setup using traditional relational database technologies such as Oracle, MySQL, Postgres etc.
8.2. Starting Spark Context¶
Let us start spark context for this Notebook so that we can execute the code provided.
from pyspark.sql import SparkSession
spark = SparkSession. \
builder. \
config('spark.ui.port', '0'). \
appName('Spark Metastore'). \
master('yarn'). \
getOrCreate()
spark.conf.set('spark.sql.shuffle.partitions', '2')
8.3. Spark Catalog¶
Let us get an overview of Spark Catalog. It is part of SparkSession object.
We can permanently or temporarily create tables or views on top of data in a Data Frame.
Metadata such as table names, column names, data types etc for these tables or views will be stored in Metastore. It is also known as catalog which is exposed as part of SparkSession object.
Permanent tables can be grouped into databases in metastore. If not specified, the tables will be created in default database.
Let us say
sparkis of typeSparkSession. There is an attribute as part ofsparkcalled as catalog and it is of type pyspark.sql.catalog.Catalog.We can access catalog using
spark.catalog.There are several methods that is part of
spark.catalog. We will explore them in the later topics.Following are some of the tasks that can be performed using
spark.catalogobject.Check current database and switch to different databases.
Create permanent table in metastore.
Create or drop temporary views.
Register functions.
All the above tasks can be performed using SQL style commands passed to
spark.sql.
8.4. Creating Metastore Tables¶
Data Frames can be written into Metastore Tables using APIs such as saveAsTable and insertInto available as part of write on top of objects of type Data Frame.
We can create a new table using Data Frame using
saveAsTable. We can also create an empty table by usingspark.catalog.createTableorspark.catalog.createExternalTable.We can also prefix the database name to write data into tables belong to a particular database. If the database is not specified then the session will be attached to default database.
Databases can be created using
spark.sql("CREATE DATABASE database_name"). We can list Databases usingspark.sqlorspark.catalog.listDatabases()We can use modes such as
append,overwriteanderrorwithsaveAsTable. Default is error.We can use modes such as
appendandoverwritewithinsertInto. Default is append.When we use
saveAsTable, following happens:Check for table if the table already exists. By default
saveAsTablewill throw exception.If the table does not exists the table will be created.
Data from Data Frame will be copied into the table.
We can alter the behavior by using mode. We can overwrite the existing table or we can append into it.
We can list the tables using
spark.catalog.listTablesafter switching to appropriate database usingspark.catalog.setCurrentDatabase.We can also switch the database and list tables using
spark.sql.
spark.catalog?
8.4.1. Tasks¶
Let us perform few tasks to understand how to write a Data Frame into Metastore tables and also list them.
Create database by name db in the metastore. We need to use
spark.sqlas there is no function to create database underspark.catalog.
import getpass
username = getpass.getuser()
spark.sql(f"CREATE DATABASE {username}_db")
spark.catalog.setCurrentDatabase(f'{username}_db')
List the databases using both API as well as SQL approach. As we have too many databases in our environment, it might take too much time to return the results
spark.catalog.listDatabases()
Create a Data Frame which contain one column by name dummy and one row with value X.
l = [("X", )]
df = spark.createDataFrame(l, schema="dummy STRING")
spark.catalog.listTables()
Create a table by name dual for the above Data Frame in the database created.
df.write.saveAsTable("dual")
spark.catalog.listTables()
spark.read.table("dual").show()
Let us drop the table dual and then database db. We need to use
spark.sqlasspark.catalogdoes not have API to drop the tables or databases.
spark.sql("DROP TABLE dual")
spark.sql(f"DROP DATABASE {username}_db")
# We can use CASCADE to drop database along with tables.
spark.sql(f"DROP DATABASE {username}_db CASCADE")
8.5. Define Schema for Tables¶
When we want to create a table using spark.catalog.createTable or using spark.catalog.createExternalTable, we need to specify Schema.
Schema can be inferred or we can pass schema using
StructTypeobject while creating the table..StructTypetakes list of objects of typeStructField.StructFieldis built using column name and data type. All the data types are available underpyspark.sql.types.We need to pass table name and schema for
spark.catalog.createTable.We have to pass path along with name and schema for
spark.catalog.createExternalTable.We can use source to define file format along with applicable options. For example, if we want to create a table for CSV, then source will be csv and we can pass applicable options for CSV such as sep, header etc.
8.5.1. Tasks¶
Let us perform tasks to create empty table using spark.catalog.createTable or using spark.catalog.createExternalTable.
Create database hr_db and table employees with following fields. Let us create Database first and then we will see how to create table.
employee_id of type Integer
first_name of type String
last_name of type String
salary of type Float
nationality of type String
import getpass
username = getpass.getuser()
spark.sql(f"CREATE DATABASE IF NOT EXISTS {username}_hr_db")
spark.catalog.setCurrentDatabase(f"{username}_hr_db")
spark.catalog.createTable?
Build StructType object using StructField list.
from pyspark.sql.types import StructField, StructType, \
IntegerType, StringType, FloatType
employeesSchema = StructType([
StructField("employee_id", IntegerType()),
StructField("first_name", StringType()),
StructField("last_name", StringType()),
StructField("salary", FloatType()),
StructField("nationality", StringType())
])
spark.sql('DROP TABLE employees')
Create table by passing StructType object as schema.
spark.catalog.createTable("employees", schema=employeesSchema)
List the tables from database created.
spark.catalog.listTables()
spark.catalog.listColumns('employees')
spark.sql('DESCRIBE FORMATTED employees').show(100, truncate=False)
Create database by name {username}_airlines and create external table for airport-codes.txt.
Data have header
Fields in each record are delimited by a tab character.
We can pass options such as sep, header, inferSchema etc to define the schema.
spark.catalog.createExternalTable?
import getpass
username = getpass.getuser()
spark.sql(f"CREATE DATABASE IF NOT EXISTS {username}_airlines")
spark.catalog.setCurrentDatabase(f"{username}_airlines")
To create external table, we need to have write permissions over the path which we want to use.
As we have only read permissions on /public/airlines_all/airport-codes we cannot use that path while creating external table.
Let us copy the data to /user/
whoami/airlines_all/airport-codes
%%sh
hdfs dfs -mkdir -p /user/`whoami`/airlines_all
hdfs dfs -cp -f /public/airlines_all/airport-codes /user/`whoami`/airlines_all
hdfs dfs -ls /user/`whoami`/airlines_all/airport-codes
%%sh
hdfs dfs -tail /user/`whoami`/airlines_all/airport-codes/airport-codes-na.txt
import getpass
username = getpass.getuser()
airport_codes_path = f'/user/{username}/airlines_all/airport-codes'
spark.sql('DROP TABLE airport_codes')
spark.catalog. \
createExternalTable("airport_codes",
path=airport_codes_path,
source="csv",
sep="\t",
header="true",
inferSchema="true"
)
spark.catalog.listTables()
spark.read.table("airport_codes").show()
spark.sql('DESCRIBE FORMATTED airport_codes').show(100, False)
8.6. Inserting into Existing Tables¶
Let us understand how we can insert data into existing tables using insertInto.
We can use modes such as
appendandoverwritewithinsertInto. Default isappend.When we use
insertInto, following happens:If the table does not exist,
insertIntowill throw an exception.If the table exists, by default data will be appended.
We can alter the behavior by using keyword argument overwrite. It is by default False, we can pass True to replace existing data.
8.6.1. Tasks¶
Let us perform few tasks to understand how to write a Data Frame into existing tables in the Metastore.
Make sure hr_db database and employees table in hr_db are created.
spark.catalog.listDatabases()
spark.catalog.setCurrentDatabase(f"{username}_hr_db")
spark.catalog.listTables()
Use employees Data Frame and insert data into the employees table in hr_db database. Make sure existing data is overwritten.
employees = [(1, "Scott", "Tiger", 1000.0, "united states"),
(2, "Henry", "Ford", 1250.0, "India"),
(3, "Nick", "Junior", 750.0, "united KINGDOM"),
(4, "Bill", "Gomes", 1500.0, "AUSTRALIA")
]
employeesDF = spark.createDataFrame(employees,
schema="""employee_id INT, first_name STRING, last_name STRING,
salary FLOAT, nationality STRING
"""
)
employeesDF.write.insertInto("employees", overwrite=True)
employeesDF.write.mode('overwrite').insertInto("employees")
spark.read.table("employees").show()
8.7. Reading and Processing Tables¶
Let us see how we can read tables using functions such as spark.read.table and process data using Data Frame APIs.
Using Data Frame APIs -
spark.read.table("table_name").We can also prefix the database name to read tables belong to a particular database.
When we read the table, it will result in a Data Frame.
Once Data Frame is created we can use functions such as
filterorwhere,groupBy,sortororderByto process the data in the Data Frame.
8.7.1. Tasks¶
Let us see how we can create a table using data in a file and then read into a Data Frame.
Create Database for airlines data.
import getpass
username = getpass.getuser()
spark.sql(f"CREATE DATABASE IF NOT EXISTS {username}_airlines")
spark.catalog.setCurrentDatabase(f"{username}_airlines")
Create table by name airport-codes for file airport-codes.txt. The file contains header and each field in each row is delimited by a tab character.
airport_codes_path = f"/user/{username}/airlines_all/airport-codes"
spark.sql(f'DROP TABLE {username}_airlines.airport_codes')
airport_codes_df = spark. \
read. \
csv(airport_codes_path,
sep="\t",
header=True,
inferSchema=True
)
airport_codes_df.write.saveAsTable(f"{username}_airlines.airport_codes")
Read data from table and get number of airports by state.
airport_codes = spark.read.table("airport_codes")
type(airport_codes)
spark.sql('DESCRIBE FORMATTED airport_codes').show(100, False)
airport_codes. \
groupBy("state"). \
count(). \
show()
8.8. Creating Partitioned Tables¶
We can also create partitioned tables as part of Spark Metastore Tables.
There are some challenges in creating partitioned tables directly using
spark.catalog.createTable.But if the directories are similar to partitioned tables with data, we should be able to create partitioned tables. They are typically external tables.
Let us create partitioned table for
ordersbyorder_month.
import getpass
username = getpass.getuser()
spark.sql(f'CREATE DATABASE IF NOT EXISTS {username}_retail')
spark.catalog.setCurrentDatabase(f'{username}_retail')
orders_path = '/public/retail_db/orders'
%%sh
hdfs dfs -ls /public/retail_db/orders
from pyspark.sql.functions import date_format
spark.sql('DROP TABLE orders_part')
%%sh
hdfs dfs -ls /user/`whoami`/retail_db/orders_part
%%sh
hdfs dfs -rm -R /user/`whoami`/retail_db/orders_part
spark. \
read. \
csv(orders_path,
schema='''order_id INT, order_date DATE,
order_customer_id INT, order_status STRING
'''
). \
withColumn('order_month', date_format('order_date', 'yyyyMM')). \
write. \
partitionBy('order_month'). \
parquet(f'/user/{username}/retail_db/orders_part')
%%sh
hdfs dfs -ls -R /user/`whoami`/retail_db/orders_part
spark. \
read. \
parquet(f'/user/{username}/retail_db/orders_part/order_month=201308'). \
show()
spark. \
read. \
parquet(f'/user/{username}/retail_db/orders_part'). \
show()
spark. \
catalog. \
createTable('orders_part',
path=f'/user/{username}/retail_db/orders_part',
source='parquet'
)
spark.catalog.recoverPartitions('orders_part')
spark.read.table('orders_part').show()
spark.sql('SELECT order_month, count(1) FROM orders_part GROUP BY order_month').show()
8.9. Creating Temp Views¶
So far we spoke about permanent metastore tables. Now let us understand how to create temporary views using a Data Frame.
We can create temporary view for a Data Frame using
createTempVieworcreateOrReplaceTempView.createOrReplaceTempViewwill replace existing view, if it already exists.While tables in Metastore are permanent, views are temporary.
Once the application exits, temporary views will be deleted or flushed out.
8.9.1. Tasks¶
Let us perform few tasks to create temporary view and process the data using the temporary view.
Create temporary view by name airport_codes_v for file airport-codes.txt. The file contains header and each field in each row is delimited by a tab character.
import getpass
username = getpass.getuser()
spark.catalog.setCurrentDatabase(f"{username}_airlines")
spark.catalog.listTables()
airport_codes_path = f"/public/airlines_all/airport-codes"
airport_codes_df = spark. \
read. \
csv(airport_codes_path,
sep="\t",
header=True,
inferSchema=True
)
airport_codes_df.createTempView("airport_codes_v")
spark.catalog.listTables()
Read data from view and get number of airports by state.
airport_codes = spark.read.table("airport_codes_v")
airport_codes. \
groupBy("state"). \
count(). \
show()
List the tables in the metastore and views.
spark.catalog.setCurrentDatabase(f"{username}_airlines")
spark.catalog.listTables()
8.10. Using Spark SQL¶
Let us understand how we can use Spark SQL to process data in Metastore Tables and Temporary Views.
Once tables are created in metastore or temporary views are created, we can run queries against the tables to perform all standard transformations.
import getpass
username = getpass.getuser()
spark.catalog.setCurrentDatabase(f"{username}_airlines")
Here are some of the transformations which can be performed.
Row Level Transformations using functions in SELECT clause.
Filtering using WHERE clause
Aggregations using GROUP BY and aggregate functions.
Sorting using ORDER BY or SORT BY
8.10.1. Tasks¶
Let us perform some tasks to understand how to process data using Spark SQL using Metastore Tables or Temporary Views.
Make sure table or view created for airport-codes. We can use the table or view created in the previous step.
spark.catalog.listTables()
Write a query to get number of airports per state in the US.
Get only those states which have more than 10 airports.
Make sure data is sorted in descending order by number of airports.
spark. \
sql("""SELECT state, count(1) AS airport_cnt
FROM airport_codes_v
GROUP BY state
HAVING count(1) >= 10
ORDER BY airport_cnt DESC
"""). \
show()
+-----+-----------+
|state|airport_cnt|
+-----+-----------+
| CA| 29|
| TX| 26|
| AK| 25|
| BC| 22|
| NY| 18|
| ON| 18|
| MI| 18|
| FL| 18|
| MT| 14|
| PQ| 13|
| PA| 13|
| CO| 12|
| IL| 12|
| NC| 10|
| WY| 10|
+-----+-----------+
airport_count = spark. \
sql("""SELECT state, count(1) AS airport_cnt
FROM airport_codes_v
GROUP BY state
HAVING count(1) >= 10
""")
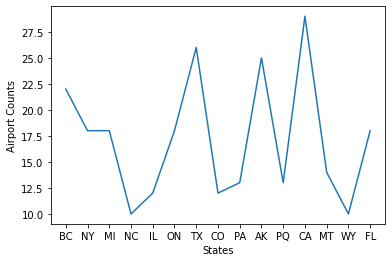
from matplotlib import pyplot as plt
airport_count_dict = dict(airport_count.collect())
states = list(airport_count_dict.keys())
states
['BC',
'NY',
'MI',
'NC',
'IL',
'ON',
'TX',
'CO',
'PA',
'AK',
'PQ',
'CA',
'MT',
'WY',
'FL']
airport_counts = list(airport_count_dict.values())
airport_counts
[22, 18, 18, 10, 12, 18, 26, 12, 13, 25, 13, 29, 14, 10, 18]
plt.plot(states, airport_counts)
plt.xlabel('States')
plt.ylabel('Airport Counts')
plt.show()